A look inside iqlusion’s Cosmos Hub Validator architecture
By Tony Arcieri and Shella Stephens
Here at iqlusion, we have taken our past professional experiences from infrastructure and security teams at notable Silicon Valley companies and applied them in building what we believe is one of the most sophisticated proof-of-stake (PoS) validators in existence today.
In this post, we’d like to provide a deep dive into how we built our Cosmos validator, the experiences that shaped our decisions, and hopefully offer some general insights into how to build a high availability datacenter networks and hybrid clouds in general.
Rather than keep this information a trade secret, we prefer to share it to help promote the security of the overall proof-of-stake validator ecosystem, and though sharing it may slightly reduce our defense-in-depth, we are firm believers in Kerckhoffs’ principle - that our infrastructure is designed in such a way that its security ultimately lies in the cryptographic keys that control its operation (well that, and proper configuration and software updates).
Without further ado, here is a diagram of our validator network architecture:
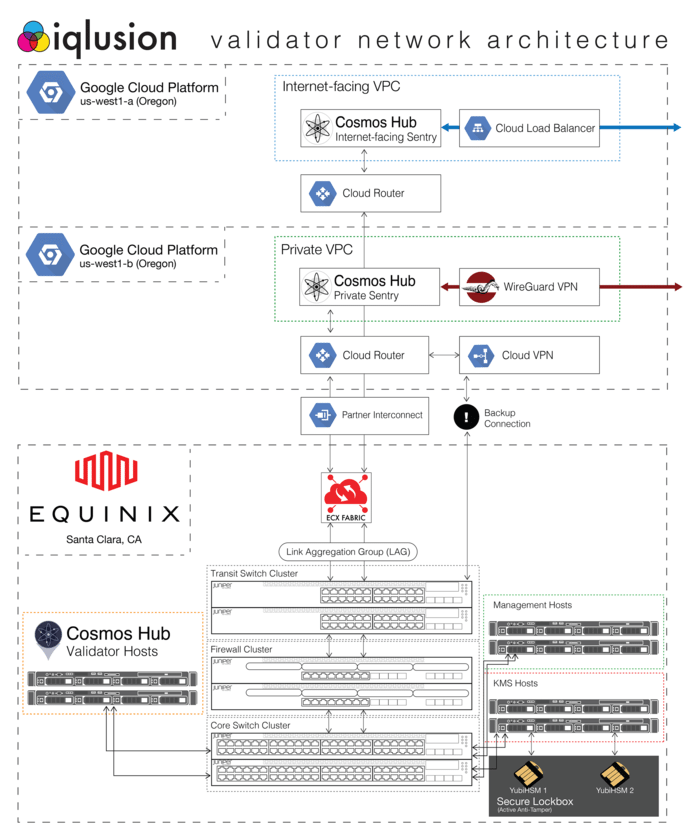
Before we dive deeper into our architecture, let’s take a step back for a second and investigate the requirements of what we’re trying to build.
What Does a Proof-of-Stake Validator Do? #
The core of the Cosmos Hub consists of a federation of validators which collectively run a Byzantine Fault Tolerant (BFT) consensus algorithm and in doing so function as a single logical computer whose compute resources can be purchased for a fee.
The security of any BFT system ultimately relies on the ability of the set of validators comprising the network to resist the influence of an outside attacker. If an attacker can gain control of more than a third of the network (by voting power, or in the case of Cosmos stake), the security guarantees of BFT break down.
Validators execute a proposed computation (i.e. a new block in a blockchain), ensure a set of constraints are upheld, and if everything checks out certify they verified the proposed computation in the form of a cryptographic signature. Therefore the core responsibility of a validator is securing an online cryptographic key and using it to certify distributed computations are performed correctly. In other words, validators provide an online key-as-a-service.
There are many other things that fall into the “online key-as-a-service” category, like every cloud key management system, the “hot wallets” at cryptocurrency exchanges, and Lightning Network nodes, or for that matter any web site that uses HTTPS encryption. In our opinion, validators fall into the highest risk category for this model, roughly equivalent to a cryptocurrency exchange or a Lightning node. Keeping a validator signing key secure, especially a heavily staked one, is a large responsibility, and one we hope we handle with due care.
The specific requirements for a validator can be found in the Cosmos Validator FAQ:
What are hardware requirements? #
Validators should expect to provision one or more data center locations with redundant power, networking, firewalls, HSMs and servers.
[…]How to handle key management? #
Validators should expect to run an HSM that supports ed25519 keys. Here are potential options:
- YubiHSM 2 […]
There are several reasons for this: the robustness of the network depends critically on it not being a monoculture of validators all running on the same platform. Cosmos Hub should not go down because AWS us-east1 is having problems.
Another reason to require hardware-backed key storage in a datacenter environment as opposed to a cloud is the desire to use cryptographic algorithms which are not available in a Cloud KMS or HSM environment (and in some cases, never will be).
As noted in the requirements above, validators are using the newer Ed25519 signature algorithm (also selected as the next-generation signature algorithm for X.509), which has a number of benefits over older signature algorithms both in terms of performance and potential use cases (e.g. interactive threshold signatures).
That said, one of the biggest bottlenecks in Tendermint, the consensus algorithm behind Cosmos, is the large numbers of Ed25519 signatures it uses, and the resulting verification time as well as bandwidth/storage requirements for all these signatures. At the moment, signatures make up the majority of the Cosmos Hub blockchain by data volume. If these bottlenecks could be eliminated through the use of more advanced cryptography, the network could potentially be significantly faster with a reduced data volume and therefore lower storage/bandwidth requirements.
There are some promising new cryptographic algorithms for doing this, such as BLS signatures which are being standardized in an IETF working group, which would allow the hundreds/thousands of Ed25519 signatures used in Tendermint consensus to be non-interactively aggregated down to a single 48-byte signature!
By requiring hardware-backed key storage, the Cosmos Hub validators will have significant agility over Cloud KMS systems in terms of adopting new cryptographic algorithms, and will be able to take advantage of these algorithms as soon as they first become available in cryptographic hardware. It will also allow us to deploy upcoming trusted computing environments, such as ones based on the RISC-V CPU architecture.
Given that, let’s talk about the hardware we have deployed and how we built our initial datacenter cabinet.
Equinix: Our Datacenter #

We selected Equinix as our datacenter hosting provider. Equinix is one of (if not the) premiere datacenter operator worldwide with over 200 facilities spanning 5 continents. The facility we’re hosted at requires 5 layers of authentication including ID verification, biometrics, and passcodes. Equinix is a popular datacenter provider for SF’s next-generation fintech companies, including some of the ones we’ve previously worked at.
Our datacenter design is influenced by our experiences as employees in other Silicon Valley companies. Here are the personal accounts of our engineering team, Tony Arcieri and Shella Stephens:
Tony: I have nearly two decades of experience in operating production infrastructure, and have always had some sort of operational responsibilities at every job I’ve worked at. I started as a system administrator for Colorado State University, where I built and maintained high performance computing clusters used for atmospheric science research. After that I worked in many security and infrastructure engineering roles, such as working on conditional access solutions for Internet TV products at Nagra/Kudelski, and as lead of the Site Reliability Engineering team at LivingSocial. Prior to iqlusion I worked at Chain where I also deployed a datacenter as a key storage environment for blockchain applications (which ended up looking a lot like a PoS validator), and before that worked on the platform security team for Square which was tasked with endpoint security, network security, intrusion detection, as well as identity and access management. I look at what we’ve built as being inspired by the design of PCI-DSS Level 1 environments used by my previous employers.
Shella: I’ve spent the past decade in multiple different infrastructure engineering roles within Silicon Valley companies. I started out doing things like automatic config management for tens of thousands of servers, and later moved on to doing multi-datacenter buildouts, including ones in China. Afterward I transitioned to a cloud team and started working on company-wide cloud automation and deployments. I’ve always wondered why people talk about the cloud versus the datacenter as if you can only pick one: why not both? My preferred hybrid cloud model is one where the datacenter acts as “mothership”, commanding the cloud environments, as opposed to handing central control of your infrastructure over to the cloud. That might make sense for companies, but we prefer to be owners of our own destiny.
Our datacenter is primarily a key storage environment for validator signing keys. Additionally, we have elected to run our Cosmos Hub validator on bare metal. This approach allows us to isolate the hosts on which we run Tendermint Key Management System (KMS) into their own firewall zone with extremely limited connectivity, such that they are completely inaccessible outside of the datacenter network. As an added twist, Tendermint KMS makes only outbound connections, and is only allowed to talk to the firewall zone where the Cosmos Hub validator hosts reside.
As you might guess from the diagram, one of our passions is network engineering. We have tried to take approaches and ideas about how datacenter networks should be designed and operated and apply them to our new buildout. In brief these are:
- No single points of failure: every component in the network has a redundant pair (i.e. N+1 redundancy). This includes everything from our transit fibers we use to connect to the cloud, to the network switches, firewalls, all the way down to the individual cables we use to connect servers to the network, as well as the servers themselves, along with their drives (all RAID-1) and their power supplies, as well as the power distribution units which power our cabinet.
- Enterprise equipment: We use Juniper switches and firewalls. While there are many enterprise network device vendors, the common themes tend to be managed equipment which boots from an immutable filesystem (with a redundant failsafe copy) which provides a unified configuration language for managing the device, such that if the component were to fail, a replacement can be easily provisioned from a backup copy of the config. Additionally, we use Dell EMC servers, all of which share an identical profile. We also have switched APC power distribution units, which allow us to do things like remotely power cycle servers.
- Segmented network: The heart of our network is a pair of Juniper SRX firewalls which authorize every single packet that flows between firewall zones / VLANs. As mentioned above we use this to heavily isolate the KMS hosts, but we have many more firewall zones, as well as a physically isolated management network. In designing our firewall zone model we have taken network segmentation practices from PCI-DSS Level 1 environments.
- Repeatable processes: All of the technology vendors and components we are using hopefully sound rather boring. There’s a reason for this: it means we can easily repeat the process, either to expand for additional growth, or in the event of disaster recovery. While there are many more exotic options we could’ve chosen, and while those may have afforded some additional defense in depth, we’ve opted to do things in ways which are routine, repeatable, and well-understood instead.
- Plan for growth: in planning out what devices to purchase, we built in considerable headroom - our combined server, storage, and network capacity is over 10X what we expect to use in the first year. While some might consider this a waste of resources, in our experience overprovisioning always ends better than underprovisioning. We would rather focus our energies on things like building out a second datacenter facility, rather than worry about upgrading our first one. As such, we have tried to build this datacenter to the same standards used at large companies, preferring to spend just a little bit more to get better equipment, even if we’re only using a fraction of its potential capacity.
Network Design #
Some specific aspects of the way we constructed our datacenter network are as follows:
- Clustered Network Devices: as you can see in the diagram above, all of our networking equipment, namely the transit switches, core switches, and firewalls which collectively comprise our network are all configured in redundant pairs. Specifically we use the EX Switch Virtual Chassis and SRX Firewall Chassis Cluster features to allow us to configure and manage both switches and firewalls as a single logical (but redundant) device. Our network is configured according to Juniper’s best practices for high availability pair chassis cluster deployments, and going forward should allow us to tolerate the failure of and perform replacement of any individual device without having to take downtime.
- Direct Cloud Connectivity w\ Redundant Link Aggregation: we transit to the outside world through dual redundant fiber optic cables which terminate in Equinix’s Cloud Exchange Fabric, their in-house Software Defined Networking (SDN) solution. These fiber optic cables are configured as a Link Aggregation Group, in which the two fibers function as a single logical connection. This allows us to leverage the combined bandwidth of both in a healthy state, and also means if one of them fails, there is no complex failover process involved. From the perspective of everything except the transit switches they’re plugged into, nothing has changed, aside from losing half of our potential bandwidth capacity. Beyond tolerating failures well, LAGs also allow us to add capacity as simply as running another fiber and adding it to the group. This means if we ever need additional bandwidth, we can just add additional (potentially faster) fiber optic cables to our existing LAG, allowing us to seamlessly and easily scale up without taking downtime.
- BGP Peering: we peer with other networks as an autonomous system using Border Gateway Protocol (BGP) - the foundational protocol upon which the Internet is based. We’re AS54687, and though you won’t find us in the PeeringDB quite yet, we’re currently leveraging BGP to peer with Google Cloud using Cloud Router. BGP allows us to have several redundant network paths (beyond just the layer 2 redundancy of the Link Aggregation Group described above), and enables routing algorithms running on our SRX firewalls which are able to pick the open shortest path regardless of the current network state. Down the road, we plan on leveraging BGP to peer directly with other validators who have also been assigned an autonomous system number. If you are a validator who has an ASN and wants to explore that in the future, please let us know!
- Bond interfaces: every server in our datacenter has redundant bonded network connections. Each server is plugged into both of our core switches, and the two physical network connections combined to function as a single logical interface. This means if ever there is a cabling issue with one of the connections, or if one of the core switches it’s plugged into dies or otherwise has issues, our servers won’t go offline, but will still have a backup connection.
- Isolated Management Network: we use a physically isolated management network to perform tasks like imaging hosts, upgrading firmware, and in the case of network devices all management tasks including configuration changes and OS upgrades. We’re big believers in the clean separation of control plane and data plane that comes from having a management network, and consider it a luxury that often goes by the wayside as companies need to scale up and cut costs (and corners).
Cryptographic Key Storage #
Providing secure conditional access to an online digital signature key is the core responsibility of a validator. The typical solution to the problem of secure storage of online cryptographic keys is to employ Hardware Security Modules (HSMs), which is the recommended approach in the Cosmos Validator Requirements mentioned above, and also one we are thoroughly familiar with from our previous employers.
We’ve selected YubiHSM2 devices from Yubico as our key storage solution. YubiHSMs are a newcomer to the overall HSM scene, but one we feel, based on previous experiences, provides a modern alternative to traditional HSMs, and in cases like Cosmos Hub where concerns like FIPS 140-2 compliance are irrelevant, YubiHSMs provide a simpler and substantially less expensive option for hardware-backed key storage which we believe provides better security in addition to access to more modern encryption algorithms, such as Ed25519, which are only just now finally making their way to traditional HSMs.
Like our other hardware, we’ve provisioned two YubiHSM2s as identical replicas (with the ability to provision more from a set of master secrets and encrypted backups). We’ve also taken additional steps to protect the physical security of these devices, which I won’t go into in detail for obvious reasons, however I will say they are kept under lock-and-key with active anti-tamper detection to ensure their physical security. These steps go beyond the many layers of security needed for physical access to our cabinet, and ensure the devices remain physically secure even in the event an attacker is able to get that far.
The primary reasons we selected YubiHSM2s for our key storage needs are as follows:
- Designed for online key storage: the intended use case of YubiHSM2 is exactly the one we’re using it for: hardware-backed key storage for servers, which means they’ve been designed to support unattended boot, i.e. if our datacenter suffers a failure of our dual redundant electrical circuits and our servers lose power, when power is restored everything is designed to come back up on its own without human intervention (and has been tested as such).
- Internal key generation support with encrypted export/import: in the cryptocurrency space, it’s common to use deterministic key generation which takes a BIP39 seed phrase and uses it to derive a hierarchy of keys using algorithms like BIP32. While this makes for a simplified recovery process where your “12 words” or “24 words” are all you need to bootstrap a replacement wallet device, it also makes for a single secret an attacker must compromise to recover all of your encryption keys. While Tendermint KMS uses a similar deterministic key generation algorithm for making administrative encryption keys, YubiHSM2s allow us to generate digital signature keys directly within the device, and export and import backups of them into other devices. These keys are randomly generated using the device’s internal cryptographically secure random number generator, which means to compromise a key an attacker needs to compromise both the master phrase and an encrypted backup of a key.
- Audit logging: actions performed by the YubiHSM2 are recorded to an internal audit log within the device. This log can be consumed by an external auditing process, which can block performing subsequent commands in the event the device’s internal log buffer fills up. We plan on leveraging this functionality to make sure all commands sent to the HSM meet our intended policies, and plan on contributing functionality to Tendermint KMS to do so as open source so all validators using YubiHSM2s can take advantage of it as well.
- General purpose: YubiHSM2s provide a wide range of functionality which is useful for securing a production environment, and can be leveraged for things like signing X.509 certificates, SSH certificates, or encrypting/decrypting data. While we use separate YubiHSM2s for these purposes beyond the ones we use for Cosmos Hub, it means there’s a single class of device that meets all of our hardware cryptographic key storage needs.
- Proven security track record: the YubiHSM product line is now nearly a decade old with a nearly spotless security track record. This is due in part with the way they are designed - by design they are not field upgradable, and because of that they have remained relatively immune to the wide range of bootloader attacks which have impacted many cryptocurrency wallets. There is a tradeoff here - responding to security vulnerabilities involves obtaining a replacement device from Yubico, however they provide these replacements free-of-charge in the event there is a security incident. That said, we think the reduced attack surface afforded by managing device updates this way is worth it, and has strategically eliminated a class of vulnerabilities which is common elsewhere. Yubico is one of the few vendors of cryptographic hardware we actually trust.
Securing and Managing Servers #
Our Dell EMC servers are all provisioned with identical hardware, and for any given role are also provisioned as pairs, however each pair is located a different firewall zone, with explicit, fine-grained policies about what traffic flows are allowable. As mentioned earlier, each is configured with dual redundant power supplies each plugged into one of our dual redundant PDUs, and each has dual redundant Ethernet cables plugged into both of our core switches (aggregated into a single bond interface).
We run CentOS Linux, a free build of RedHat. We are heavy users of many other distributions, including Alpine Linux for containers, and are also long-time Debian users who continue to use it for personal projects. That said, here are the reasons why we chose CentOS for a greenfield production infrastructure:
- Secure Boot: CentOS supports Secure Boot out-of-the-box using a UEFI shim signed by a key which is pre-provisioned on our servers. While in the future we could manage the Secure Boot chain ourselves which would enable using distributions which don’t yet have out-of-the-box secure boot support, as a validator and a small team we are already up to our eyeballs in cryptographic keys, and are glad there are solutions for secure boot without the need to manage additional cryptographic keys and sign every kernel upgrade ourselves.
- SELinux: RedHat distributions come with Security-Enhanced Linux enabled by default. While it’s exceedingly common for people to shut SELinux off rather than attempt to use it (it’s somewhat notorious for being obtuse), we leverage it and have integrated it into all of our processes. The exact value of doing so is debatable, and we would not be surprised if sophisticated attackers are able to bypass it, however where we do think it provides value aside from directly stopping threat actors, namely as an enforcement tool for secure configurations. SELinux enables setting of central policies which enforce best practices for securely deploying software and we believe it is useful, at the very least, for preventing certain types of misconfigurations which would result in a security issue from ever happening in the first place.
- Atomic Host Upgrades: software updates on hosts are typically performed by using a configuration management tool to drive the OS package manager, and attempt to converge the set of installed packages with a pre-defined set. The complexities around this approach, including unintentional breakages of deployed software, hosts winding up in inconsistent states, and overall incomprehensibility of the associated tooling are among reasons why these tools are reviled and container-based deployments have gained popularity. Project Atomic, a RedHat project with extensive CentOS support, is developing a set of tools which both bring container-like ideas to bare metal hosts, and also provide streamlined container management. The rpm-ostree tool provides an alternative mechanism for updating bare metal hosts: instead of using a configuration management tool to drive the OS package manager, it builds a new filesystem from a centrally published image which exists in tandem with the currently running one. When it’s finished, a host reboot (which you’ll want to do anyway if the kernel has been upgraded, which it almost certainly has) switches over to the newly created filesystem image. If there’s a problem, the old one is still there, enabling rollback in the event of host upgrade issues. We believe applying the concepts of immutable infrastructure to how we manage bare metal hosts eliminates many of the problems around software updates, and also facilitates things like producing containers which are derived from the same image as bare metal hosts.
- Enterprise Focused: we rely on CentOS to deliver many types of software updates, including CPU microcode updates needed to address microarchitectural attacks like Spectre, Meltdown, and Foreshadow. While we could obtain these updates out-of-band directly from Intel, we are a small team with many responsibilities, and seek to find secure solutions for simplifying our operations. Other distributions do not necessarily have CentOS’s enterprise focus, and may compromise on shipping things like microcode updates due to political disputes over the licensing terms. We applaud these distributions for taking a principled stand, but at the same time, our immediate needs are around infrastructure security and as such we’d prefer to receive these security updates in a timely manner.
- Ubiquity: There are certainly many other distributions to consider beyond CentOS and Debian. However, the other thing CentOS has going for it is an immense amount of traction. CentOS support, whether in documentation or the software itself, is ubiquitous and we do not find ourselves saying “if only they supported CentOS” about software we wish to leverage.
Aside from CentOS, here are some additional details about how we deploy and manage servers:
- Automated Host Imaging: we perform OS installs and upgrades through an automated remote imaging process which is Secure Boot-compatible. This was no easy task, and we plan on blogging about our specific approach in the future.
- In-house Configuration Management Tooling: configuration management is the electric third rail of production infrastructure - few are happy with any of the available options, and they are all rather heavy-handed, requiring considerable investment and expertise to deploy and maintain. That said, some solution to the overall problem is necessary to run a secure infrastructure - operating without one is a great way to ensure your servers aren’t correctly upgraded and wind up misconfigured or otherwise in inconsistent states. We hope to leverage tools like
rpm-ostreementioned above to perform the package management-related functions of a configuration manager, however that still leaves the rather mundane problem of delivering configuration files to servers securely, ensuring updates to them do not break running services, and that all managed configuration files are subject to file integrity monitoring to ensure unintended changes to these files are both detected and reverted. To these ends, we have developed an in-house tool specific to the needs of managing configuration files. It pervasively leverages cryptography to ensure the authenticity, integrity, and confidentiality of configuration files, enabling all updates and rollbacks to host configuration be authorized through the use of hardware-backed cryptographic keys, and enabling secure management of files containing secrets. The tool is named “Placer”, it’s written in Rust, and so far it’s been flawlessly performing its job for our infrastructure. It’s presently an in-house-only closed source tool, however we plan on open sourcing it later this year as one of many “CryptOps” tools we use internally. - In-House Deployment Tooling: our hybrid cloud leverages many of the same applications in both the cloud and datacenter, including both our in-house tooling developed in Rust, and also Go applications including the Cosmos SDK. Both Rust and Go are amenable to static linking, and the interesting thing about static linking is it eliminates the need for container images to contain an entire Linux distro filesystem - instead you can create containers which contain only the application executables and support files, as opposed to shoving an entire distribution image into every container. This minimalist approach to containers, branded by Google as “Distroless” containers, has many positive benefits for security. We’ve written our own deployment tooling for unifying Docker-based distroless deployments as well as bare-metal deployments on our datacenter host, while supporting a fully containerized build-workflow (including deploying from container registries) and with the goal of targeting upcoming “microVM” tools such as Amazon Firecracker which we feel are good targets for “distroless” application workloads and an ideal way to virtualize deployment of our datacenter application workloads. These tools are written in… you guessed it, Rust, and we are using them in production today without issue for managing all of our deploys. We hope to announce an open source release of these tools later this year.
Now that we’ve looked at how we built and managed our datacenter deployment, let’s change gears and take a look at the other side of our hybrid cloud: how we leverage Google Cloud Platform.
GCP: Our Cloud #

We use Google Cloud Platform (GCP) as our primary cloud provider. While we have ample experience with alternatives including over a decade of experience with Amazon Web Services (AWS), and plan on leveraging it as a backup and for VPC peering with other validators, we chose to start with GCP over AWS, and so far have not regretted it.
For the purposes of avoiding making this already quite long post even longer we’ll avoid going into details for now (saving them instead for a potential future blog post), but in broad strokes GCP feels more refined than AWS with a more solid technological foundation, better performance, simpler operation with less incidental complexity, and Identity and Access Management (IAM) which is better hardened by default. As network engineers we are quite impressed with the Andromeda network virtualization stack GCP uses, and how it enables features like Live VM Migration.
In the rest of this post, we’d like to describe how we leverage GCP to for the purposes of our Cosmos Hub Validator.
Cloud Overview #
Our primary workload deployed on GCP is our Cosmos Hub sentry nodes. These are Cosmos Hub “full nodes” which communicate with other validators and other Cosmos Hub nodes over a peer-to-peer overlay network, and serve to insulate our validators from the outside world.
No messages are sent to the validator until first verified by one of these sentries, which effectively perform a sort of “pre-validation” step as a full node in the network.
We operate two types of sentries: Internet-facing sentries which use public IP addresses, and private sentries (which we internally refer to as out-of-band or “OOB”) which do not have a public IP address and can only be reached by an RFC1918 private IP address (when we say “private” sentry, we really mean it!). To reach our private sentries, we’ve deployed the up-and-coming WireGuard VPN software, which uses modern cryptography and terminates the VPN inside of the Linux kernel, providing excellent performance. We also support GCP VPC Peering, so if you are a fellow validator who would like to peer with us and are interested in either of these private peering methods, let us know!
As mentioned above, we use BGP peering from our datacenter to provide multiple redundant paths to the cloud. We have two instances of Cloud Router deployed, each in separate availability zones (i.e. us-west1a and us-west1b), ensuring that in the event of a total outage of one availability zone (which is theoretically a completely independently operated datacenter facility), the other will remain available.
For the time being, we’ve deployed our public-facing sentries in us-west1a, and our private sentries in us-west1b, each in their own isolated VPC. In each of these VPCs, we generally have one sentry active at a given time, along with a “hot spare” ready to take over in the event it fails.
All of our compute workloads are presently deployed on Compute Engine, GCP’s VM service, utilizing Google’s Container-Optimized OS (cos), a hardened Linux hypervisor for Docker containers which is effectively the server-side equivalent of ChromeOS. Notably, cos is also the OS used as the hypervisor for GCP’s Kubernetes Engine, so while we aren’t yet leveraging Kubernetes, we have our workloads deployed in a way which would make it easy to transition to doing so.
Cloud Build: Our Build System #
As part of operating a validator we do quite a few builds: container images for cloud deployment, builds of the Cosmos SDK and Tendermint KMS, and builds of production tools we develop in-house which we deploy as signed RPMs through a yum repository hosted on Cloud Storage.
We build all of these things using GCP’s Cloud Build service in conjunction with Cloud Source Repositories, their private Git repository service. Cloud Build is a heavily container-oriented build tool, allowing build steps to be decomposed into separate docker containers that operate on the same filesystem image. For example, we have an image for atomic-reactor, a RedHat-oriented tool for building container images developed as part of Project Atomic.
After containers are built, they are uploaded to Container Registry, GCP’s private Docker container registry. We deploy everything from GCR, both in the cloud and in the datacenter (and that said, one of the best aspects of greenfielding a hybrid cloud is being able to integrate cloud tooling like this into our datacenter operations workflow).
Identity Aware Proxy: Our Front Door #
We run a number of internal tools to manage operations, and need some way to get access to them. GCP provides a great solution for this: Identity-Aware Proxy (IAP), an authenticated web proxy which allows you to set fine-grained access control policies about what resources particular users are allowed to access. It can even be used for SSH tunneling.
IAP is a subcomponent of GCP’s larger Cloud Identity services, which we leverage as our identity provider. Together with Security Command Center’s access control monitoring and anomaly detection, as well as Security Key Enforcement, which requires all members of our org are strongly authenticated using a hardware token, we believe this solution provides BeyondCorp-like security properties, considered to be the state-of-the-art today.
One final shout out: in addition to Google’s identity and access control services, we also simultaneously leverage Duo Security to provide an additional layer of authentication beyond Cloud Identity. We require both in conjunction for production access, but as Duo also provides BeyondCorp-like services, we will be comparing them to the offerings from Google and keeping them in mind.
Conclusion #
We hope you’ve enjoyed this post! There are many things we wanted to cover but did not. We’re excited about covering them in future blog posts, in particular tooling we’ve developed in-house for datacenter operations. If there’s something in particular you hoped to see covered which we did not, feel free to contact us on Twitter or email us.
What’s next for us? Probably more datacenters, more clouds, more protocols, more assets. Diversifying our infrastructure will improve our validator’s robustness. We are also excited about the prospect of hosting many more Tendermint networks than just the Cosmos Hub, such as the IRIS Network and potentially other proof-of-stake networks like Tezos, who recently announced they’ll be switching to Tendermint’s consensus protocol. We’re excited to see what the future brings, particularly around things like the Inter-Blockchain Communication (IBC) protocol.
In building out our infrastructure, we have sought to walk the fine line between security and agility: implementing all of the most common security best practices while ensuring agility around our ability to scale out and run new networks and new software. We fundamentally believe that a distributed custodian like the Cosmos validators should be secured with institutional grade setups for each validator, and also, that our ability to remain simultaneously both secure and agile is the nuance of iqlusion.